A behind-the-scenes look at how we built Eon, learned from it, and open-sourced every component.
Agents are the new developers.
They read, write, and build on our behalf. But the systems they rely on were designed for humans. Agents need infrastructure that can remember context, reason over data, and act in real time.
At Tiger Data, we set out to build that foundation: a database built for agents. But before we could build for them, we needed to understand what it actually takes for one to work in the real world.
So we built Eon, a Slack-native assistant that turns institutional knowledge into instant answers. Within 6 weeks, nearly 50% of the company has been using it every day.
Slack was the perfect environment for the experiment. It’s where our fully remote team works, makes decisions, and shares context daily. It’s also a natural medium for conversation. Tools like ChatGPT, Claude Desktop, and Claude Code have already made chat the default interface for language models. We wanted Eon to feel the same way: like another teammate, but with perfect recall.
Building Eon taught us what agents truly need to operate in the real world: memory, context, and reliability. Each began as an engineering challenge and became an open-source component.
Over six weeks, we tackled three fundamental problems. First, we had to give Eon conversational memory—the ability to follow context across threaded discussions. Then, we needed to provide focused context from our entire knowledge-stack: GitHub, Linear, and documentation. Finally, we had to make it reliable enough that half the company could depend on it daily. Here's how we solved each, what we learned, and what we open-sourced along the way.
(If you want to skip the story and start building, below are the names of the open-source repos. Or jump to Eon: Putting It All Together.)
- tiger-eon - Our reference implementation
- tiger-agents-for-work - Production-ready Slack agent framework with durable event processing, retries, and bounded concurrency
- tiger-slack - Real-time Slack ingestion and conversational memory storage in TimescaleDB
- tiger-docs-mcp-server - Semantic search over PostgreSQL/TimescaleDB documentation
- tiger-gh-mcp-server - Focused GitHub tools for PR and issue retrieval
- tiger-linear-mcp-server - Focused Linear tools for task tracking
We will begin with the first challenge every agent faces: memory.
Challenge 1: Building Memory That Understands Time
Making Eon feel natural meant solving a fundamental problem: conversation. When humans chat, we follow the flow of the conversation. Singular statements or questions in isolation can be considerably vague and confusing, but make perfect sense when taken in context. We wanted Eon to do the same.

When a user mentions Eon in a message, Slack sends an app_mention event that contains only that single message. There is no thread context or conversation history. Users could include all the background in every question, but that would break the illusion of chatting with a teammate.
We needed Eon to remember what happened before and understand how conversations evolve. Memory, we realized, isn’t just storage, it’s also time: the sequence, order, and relationships between messages.
That insight reframed the problem. Slack conversations are time-series data. Events unfold moment by moment, each with a timestamp, sender, channel, and parent message. Their natural structure is temporal, and TimescaleDB was built to reason over time.
So we built a real-time ingestion system that captures every message, reaction, edit, and update from Slack—and can also backfill years of history from exports. All data flows into TimescaleDB, where it’s queried directly using SQL with no rate limits or complex APIs to wrangle.
This gave Eon conversational memory—the ability to recall what was said, when, and by whom—and revealed something deeper: building memory means building systems that understand time. That's something TimescaleDB handles naturally.
We open-sourced this as tiger-slack: a production-ready system for Slack ingestion and conversational memory storage in TimescaleDB.
Challenge 2: Providing Context Without Noise
Eon had conversational memory, but needed additional context. Slack holds a wealth of institutional knowledge, but it’s not the whole picture. Engineering discussions happen in GitHub pull requests. Progress is tracked in Linear tickets. Technical answers sit deep in documentation. To be truly useful, Eon needed access to all of it.
That's where the Model Context Protocol (MCP) came in. It provides a standard for connecting agents to external tools and data. Instead of wiring integrations directly into Eon, we built small, composable MCP servers, each focused on a single source of context.
But here's what we learned: not all MCP servers are created equal.
Official MCP servers exist for GitHub and Linear, but they're designed for general-purpose assistants. They expose dozens of tools across every API endpoint. That flexibility is useful for broad assistants, but inefficient for a focused one like Eon. Too many tools increase token usage, raise cognitive load for the model, and make errors more likely.
Filtering those tools down doesn't solve the problem. The official versions are wrappers around APIs that are themselves wrappers around database schemas. Getting the needed information often requires multiple tool calls and stitching together results—something an LLM can do—but unreliably and at high token cost.
Instead, we built MCP servers with tools designed around what users actually ask for, not around API endpoints. These tools provide just enough high-quality context that the agent can execute its task effectively–no more, no less. This is context engineering at work.
For example, in our tiger-linear-mcp-server, we created a get_issues tool with a simple interface:
get_issues(user_id, project_id, updated_after)Under the hood, this makes numerous calls to the Linear API: first, it fetches the filtered set of issues, and then for each issue, it fetches comments, attachments, label details, project details, state, team information, and user details. It caches everything to avoid duplicate requests and projects it into a clean, understandable object shape with no duplication.
An LLM could theoretically assemble that sequence using the official Linear MCP server, but it would be slower, less reliable, and far more expensive in tokens. We provide a single tool that does exactly what our users need.
For GitHub, we built focused tools for searching pull requests, retrieving issue discussions, and summarizing commit history. No repository management. No CI/CD controls. Just read-only access to the information that answers users' questions.
For documentation, we built a semantic search engine over PostgreSQL, TimescaleDB, and Tiger Cloud docs, powered by pgvector. It also includes expertly written auto-discovered prompt templates with knowledge about common tasks like schema design. When someone asks a technical question, Eon retrieves and cites the real docs. Unlike "prompt libraries" released by other companies, you don't need to copy and paste some PROMPT.md into your code; your coding agent automatically makes that decision itself. It's seamless, and you don't need to think about it.
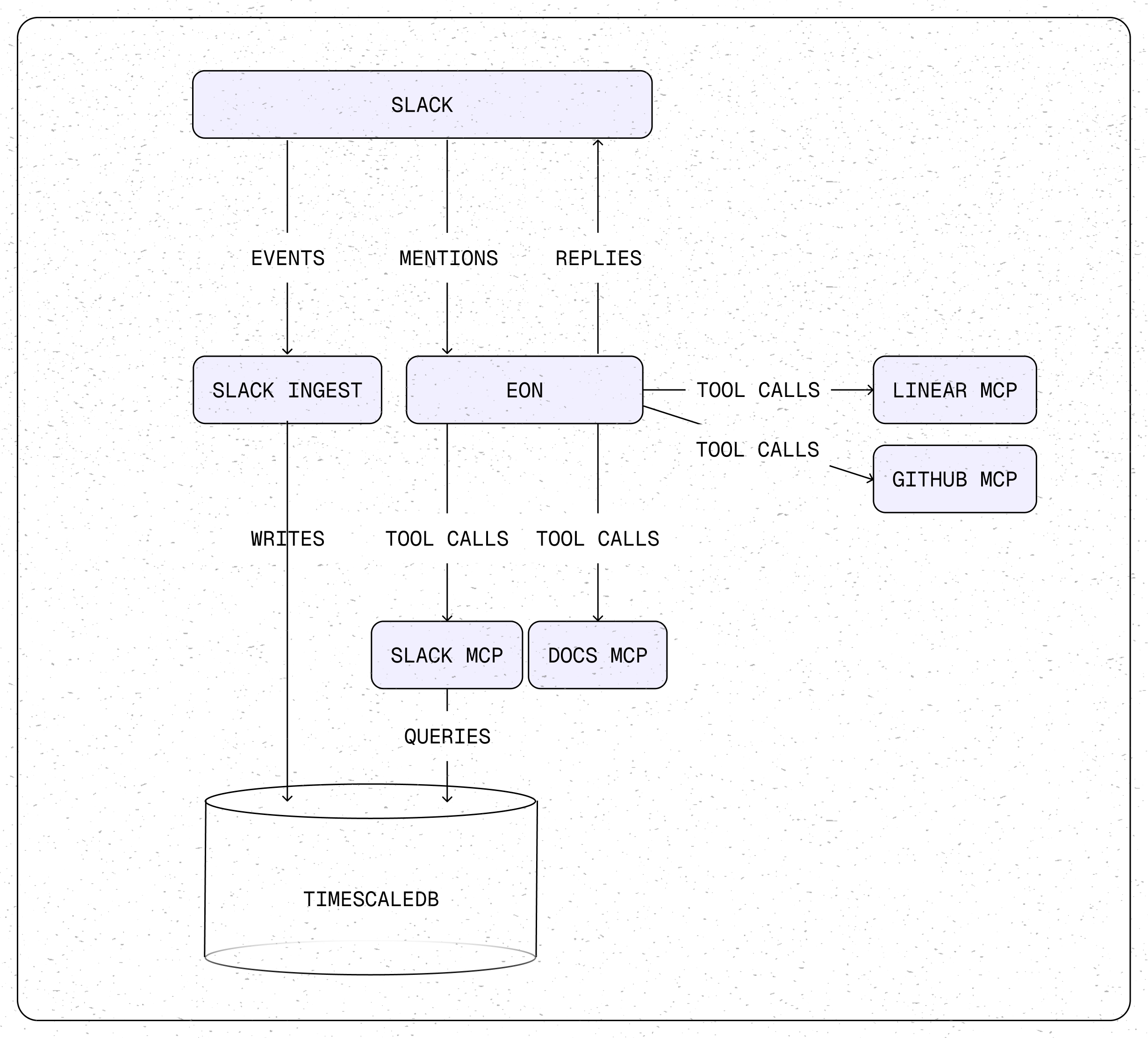
This modular design means each component can evolve independently. We've improved our documentation search three times without touching Eon's core. We've added new GitHub query patterns based on user questions, without changing a single line of agent logic. Want to add Salesforce data? Build a new MCP server, plug it in, and test it. That's the power of focused, composable context.
We open-sourced all of it: tiger-gh-mcp-server for GitHub, tiger-linear-mcp-server for Linear, and tiger-docs-mcp-server for documentation search. The docs server is also publicly available at mcp.tigerdata.com/docs—add it to Claude Desktop or Claude Code to bring PostgreSQL and TimescaleDB expertise into every session.
Challenge 3: Making It Reliable
MCP servers solved the context problem, but we still had to tackle another essential one: reliability.
When nearly half your company depends on an agent for answers, it can’t just work most of the time. Every question matters, and every answer removes a potential obstacle. We wanted Eon to deliver consistently.
Let's be clear: errors happen. And when working with non-deterministic systems, like an LLM, unexpected things occur frequently. Most Slack bot tutorials show you how to respond to an event, but not how to handle the realities of production. What happens when your bot crashes mid-conversation? What happens when the GitHub API goes down? What happens under load when dozens of people are asking questions simultaneously?
We're a database company. We know how to build durable, reliable systems. So we built a production-ready library for Slack-native agents with four core capabilities:
Durable event processing: Each Slack event is written to Postgres before we attempt to process it. If the bot crashes, no events are lost, they remain in the queue to be processed. Workers claim events using row-level locking, which allows multiple bot instances to run concurrently without conflicts.
Automatic retries: Events that fail are left in the queue and automatically retried up to three times with a ten-minute delay to give transient issues time to resolve. In practice, this means virtually every user question gets answered.
Bounded Concurrency: We use fixed-size worker pools to prevent resource exhaustion. When traffic spikes, the system doesn't crash. Instead, it processes events as quickly as possible, queuing the rest in PostgreSQL until workers become available.
Millisecond latency: Workers poll the queue table to claim events, which naturally handles retries and recovery. But polling introduces latency. We didn't want users waiting for the next poll cycle, so we use asynchronous signaling to "poke" a random worker immediately when a new event arrives. The result: Eon typically responds in milliseconds, even though it's built on a durable queue.
The result is a Slack agent that feels instant to users but is built like production infrastructure: durable, observable, and horizontally scalable.
We open-sourced this as tiger-agents-for-work: a library that handles all the production infrastructure, so you can focus on your agent's logic, not durable queues and retry mechanisms.
Eon: Putting It All Together
tiger-eon is our reference implementation, a lightly edited version of the Slack agent we deployed internally, which our team uses daily. It's also a blueprint for assembling these building blocks into a functioning system. You can easily install and try it out using a simple installation script.
At its core, Eon is surprisingly simple. It's built on tiger-agents-for-work for reliable event handling, uses tiger-slack for conversational memory, and plugs in MCP servers to access GitHub, Linear, and documentation. Everything runs as stateless services coordinated through Tiger Data.
The architecture looks like this:
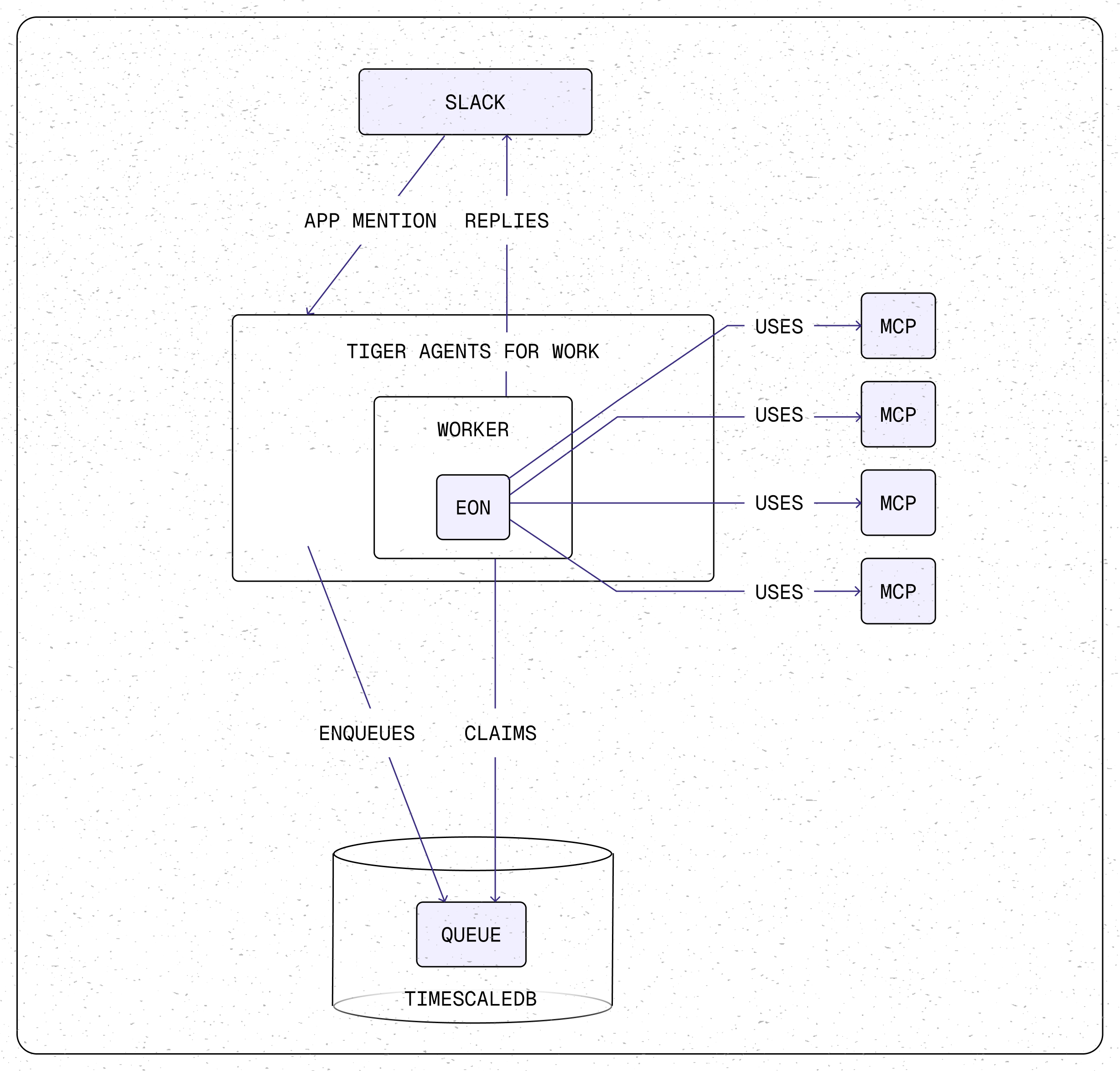
- Slack app_mention events flow into the tiger-agents-for-work event queue
- Workers claim events and invoke the Eon agent
- Eon decides what information it needs and calls the appropriate MCP servers (e.g., Slack history, GitHub PRs, documentation, etc.).
- MCP servers query their respective data sources and return structured results
- Eon synthesizes the information and responds in Slack
Configuration, Not Code (Unless You Want To)
One of our design goals was to make Eon easy to customize without writing code. The entire setup is driven by configuration files, not Python modules you need to understand and modify.
Want to add a new data source? Add an MCP server to your mcp_config.json. Want to change how Eon introduces itself? Edit a Jinja2 template. Want to swap out Claude for a different LLM? Change a CLI argument or environment variable. The architecture separates concerns: configuration data defines what Eon can do, while the code handles how it does it.
We provide an interactive setup script that walks you through the entire process. It prompts for your API tokens, generates the configuration files, and spins up everything using Docker Compose backed by a database on the Tiger Cloud Free Plan. From git clone to a working agent answering questions in Slack: approximately 10 minutes.
However, when you need to dive deeper, customize business logic, specialize tool selection, or prefetch context from internal systems, tiger-agents-for-work is a library, not just a CLI. Subclass the base agent, override its methods, and you have full programmatic control. The framework handles the production infrastructure (durable queues, retries, concurrency) while you focus on the logic that's specific to your needs.
The result: you can get an agent running quickly, then evolve it into something completely custom without rewriting the foundation.
From What We Learned to What You Can Build
Building Eon taught us something important: AI agents don't need exotic infrastructure. They need durable event handling, structured memory, and focused tools. Agentic Postgres provides the foundation, built on the operational maturity and ecosystem of Postgres that most teams already have.
And we didn't build a demo or a prototype. We built production infrastructure that our company depends on daily. Now we're releasing everything as open-source, composable components you can deploy together or separately.
Start with tiger-eon, our reference implementation. Clone it, run the interactive setup script, and you’ll have a working agent answering questions in your Slack workspace in minutes.
Go deeper with the components:
- tiger-agents-for-work - Production-ready Slack agent framework with durable event processing, retries, and bounded concurrency
- tiger-slack - Real-time Slack ingestion and conversational memory storage in TimescaleDB
- tiger-docs-mcp-server - Semantic search over PostgreSQL/TimescaleDB documentation
- tiger-gh-mcp-server - Focused GitHub tools for PR and issue retrieval
- tiger-linear-mcp-server - Focused Linear tools for task tracking
Each repository includes setup instructions and can be run in a Docker container. Use them together to replicate what we built, or mix and match to create something entirely new.
This is the first project from our team, marking the beginning of a larger journey. We will continue to build more agentic capabilities and infrastructure, making it easier for developers to build AI applications all on Postgres.
Agents are coming online, and with Tiger Data, they finally have the database built for them.
(If you build with Eon, show us what you’ve made. Open an issue, submit a PR, share it on social media, or join our community Slack to chat with Eon, it’s live and answering TimescaleDB questions.)
About the author
John Pruitt
John Pruitt is a Staff Engineer on the AI team at Tiger Data, where he builds AI-native applications and tools on Postgres. With over 22 years of professional experience, John has spent his career building greenfield systems with small teams under tight timelines, often requiring novel solutions that still had to be production-grade from day one.
Prior to Tiger Data, John led software engineering, data warehousing, and database administration efforts primarily in the financial services and power industries. Throughout his career, he's worked extensively with relational databases and time-series workloads, including building a bi-temporal database model from scratch on Postgres. It's this deep background that makes him particularly passionate about using PostgreSQL for bleeding-edge AI applications.
John holds a Bachelor of Software Engineering from Auburn University and a Master of Engineering from UAB.